Neuronové sítě
Úvod
Jedním z cílů informatiky a výpočetní techniky je vytvoření umělé inteligence. To znamená vytvoření stroje, který by byl schopen samostatného učení a operativního reagování v podmínkách komplexního prostředí, a tedy mohl pracovat bez přesného vnějšího řízení.
Klasická teorie umělé inteligence se snaží dosáhnout schopností vyšší nervové soustavy prostřednictvím deduktivních algoritmů. Charakteristická je přitom přesná lokalizace informace v paměti a její v podstatě sekvenční zpracování - způsob práce současných počítačů.
Zde se však narazilo na teoretické meze - většina úloh umělé inteligence buď není algoritmicky řešitelná vůbec, nebo s exponenciální složitostí. člověk však tyto úlohy v řadě případů úspěšně řeší. Pozornost se tedy zaměřuje na "hardwarovou realizaci" lidských schopností, tedy na nervovou soustavu a její strukturu.
Neurologická exkurze
Nervová soustava se skládá z bohatě rozvětvených nervových buněk (neuronů), vedoucích vzruchy. Výplň mezi neurony tvoří drobné, bohatě rozvětvené buňky - neuroglie (glie). Tyto buňky vzruchy nevedou, vyživují neurony a odvádějí odpadní látky metabolizmu v nervové tkáni. Okolo dlouhých výběžků neuronů tvoří Shwanovy buňky ochranou Shwanovu pochvu, pod kterou se na mnohých vláknech vytváří myelinová pochva.
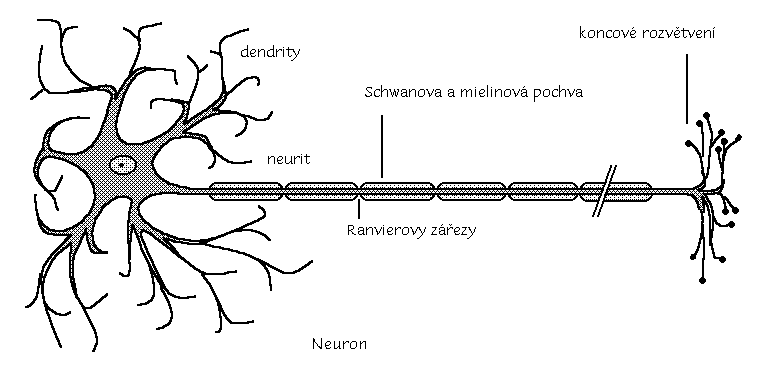
Neuron je vysoce specializovaná buňka, z jejíhož těla vybíhá mnoho větvících se výběžků (dendritů) a jeden nápadně dlouhý výběžek (neurit, axon), který je zakončen synapsí (zápojem). Tady neurit přisedá obvykle k jinému neuronu (nebo k nervosvalové ploténce).
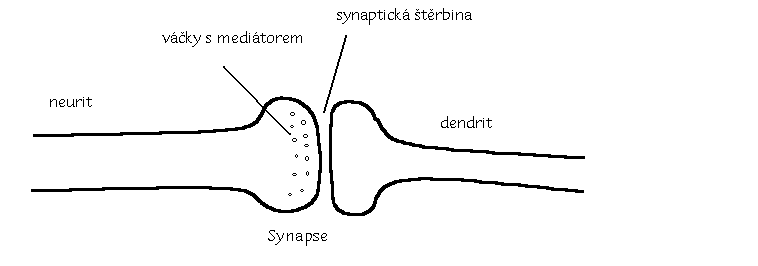
Neuron má svou vnitřní aktivitu, která je závislá na jeho historii (např. dosavadním průběhu aktivity) a na dráždění ostatními neurony nebo receptory. Pokud tato aktivita přesáhne určitý práh, neuron vyšle po neuritu signál (říkáme, že neuron pálí). Tento signál můžeme registrovat jako elektrický děj. Ten je však zprostředkován pohybem iontů, nikoli elektronů. Rychlost vzruchu závisí na síle mielinové vrstvy (ta izoluje neurit od ostatních neuronů) a pohybuje se od 0.5 m/s do 120 m/s. Když vzruch dojde k synapsi, elektrický signál se mění na chemický. V zakončení neuritu jsou váčky obsahující mediátor (neurotransmitér). Ten se uvolní do synaptické štěrbiny. Na druhé straně synapse je mediátor zaznamenán chemoreceptory a vzruch je opět převeden na elektrický signál.
Zdá se však, že informace není uložena pouze v tom, zda neuron pálí, či nepálí, ale že je uložena ve frekvenci pálení. Situace je dále komlikována tím, že přenos vzruchu přes synapsi může být uskutečňován různými mediátory. Ty mohou mít různou dobu působnosti nebo mohou cílový neuron dráždit, či tlumit. Při delším dráždění vykazuje neuron tzv. adaptaci - pokles frekvence při stejné intenzitě vstupů. U nervové soustavy můžeme pozorovat tzv. sbíhavost (k jednomu neuronu přicházejí nervové signály z většího počtu jiných neuronů) a rozbíhavost (jeden neuron vysílá signáli k většímu počtu jiných neuronů, protože se neurit může větvit).
Jedna z vlastností mozku, který realizuje všechny složitější funkce nervové soustavy, je dynamická lokalizace analyzátorů - ačkoli se podařilo najít umístění mnohých senzorických analyzátorů a efektorů, přece se občas stane, že někdo přijde o značnou část mozku, aniž by to nějak výrazně ovlivnilo jeho chování.
Historie neuronových sítí
V době, kdy se konstruovaly první elektronické počítače založené na logických hradlech se jako doprovodný jev počítačové euforie oběvila představa, že je-li hradlo cosi funkčně podobné neuronu, pak mozek není nic jiného než gigantický počítač. Proto byli nejdříve konstruovány základní logické prvky - perceptrony. Avšak pokusy sestavit perceptrony do větších a přitom funkčních celků neuspěly. Z neurologie bylo jasné, že záleží na kvalitě spojení (synapsí) a na topoligii sítě. Nepodařilo se však najít účinný výukový algoritmus, který by spojení nastavoval, ani nebyla známa topologie mozku. Vlna zájmu o neuronové sítě postupně utichla. S rozvojem výpočetních prostředků v 70-tých letech se zájem vrací. Záhy byl oběven tzv. backpropagation algoritmus, který umožnil praktické využití perceptronových sítí. Zájem o neuronové sítě je nyní daleko praktičtější, původně neurologické přístupy jsou značně zjednodušeny. Mnohé sítě jsou používány při konstrukci netipických počítačů. Zároveň s technickými aplikacemi se však znovu oběvují pokusy modelovat chování nervové soustavy.
Typy neuronových sítí
Základním kritériem pro čleměmí sítí je, zda byly vytvořeny pro praktické aplikace nebo pro neurologické modelování.
Neurologické modely
Neurologické modely jsou ty modely, které se snaží objasnit činnost nervové soustavy. Po nezdaru s nestrukturovanými perceptronovými sítěmi je jasné, že struktura nervové soustavy je příliš složitá, než aby bylo možné vytvořit relativně jednoduchý model, odrážející její chování.
Další způsob modelování nervové soustavy je vycháze z vyšších neururonových struktur, než je jediný neuron. Ale tyto struktury jsou spíše anatomické a jejich funkční smysl není zatím znám. Tato neznalost je ovšem tvůrcům modelů značně na obtíž.
Jinou cestou při modelování nervové soustavy je všímat si u jednotlivých praktických úloh shodných rysů jako téměř vedlejších efektů.
Aplikační modely
Vzestup zájmu o neuronové sítě je výsledkem praktických potřeb, takže tyto modely dnes značně převažují. Nicméně celá řada architektur se snaží poukazovat na souvislost některých rysů svého chování s chováním vykazovaným přirozenými systémy. Neuronové sítě mohou pracovat v zásadě třemi způsoby:
- určení, do které třídy možných vstupů patří daný vstup
- obsahově adtesovaná paměť - vstupem je neúplný či porušený exemplář, na výstup žádáme celý exemplář
- tzv. "clustering" - redukce vstupních dat bez stráty relevantní informace (např. různým výslovnostem slova přiřadit jeho význam
Síť tak vlastně pokaždé pracuje jako třídič vstupů. Třídy, které má rozpoznávat je třeba ji naučit - hovoříme o síti s učitelem (supervizored net), nebo si je síť vytváří sama na základě vstupních dat - tzv. síť bez učitele (unsupervizored net). Sítě s učitelem bývají užívány v oblastech 1. a 2., sítě bez učitele v oblasti 3.. Vůči klasickým třídičům mají neuronové sítě řadu předností:
- podstatně větší rychlost
- robustnost: lokální poškození nemusí globálně vadit, pouze snižuje přesnost
- menší parametrická náročnost - sítě si řadu parametrů určí samy v procesu učení
Neuronové sítě můžeme rozdělit do různých kategorií. Jednoduché členění předvádí Lippmann:
Typy neuronových sítí
| s binárním vstupem | s učitelem |
| bez učitele |
| se spojitými vstupy | s učitelem |
| bez učitele |
Toto členění však nebere v úvahu struktutu sítě. členění podle struktury sítě vypadá takto:
Typy neuronových sítí
| nesrukturované |
| strukturované | kompetiční modely |
| hierarchické |
V nestrukturovaných sítích jsou všechny neurony rovnocenné, síť je homogení, bez strukturálního členění. Ve strukturovaných sítích můžeme rozlišit různé nestrukturované podsítě - vrstvy. V hierarchických sítích jsou jednotlivé vrstvy stejného typu, kdežto v kompetičních modelech mhou mít vrstvy různý typ spojení a vykonávat různé funkce. Typicky je nižší vrstva vstupní a vyšší jsou rozhodovací. Základní popis architektury je zadán:
- popisem výpočetního elementu (formálního neuronu)
- popisem topologie sítě
- zadáním výukových pravidel
V podstatě všechny aplikační sítě používají tento výpočetní element:
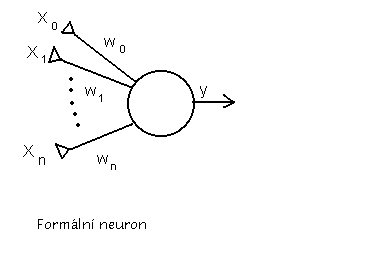
y=f(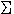 wixi+
wixi+ )
)
xi jsou vstupy
wi jsou váhy vstupu
je vnitří práh pálení
Jako signální funkce se užívají:
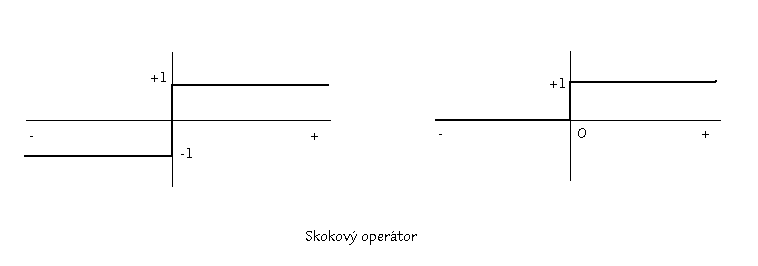
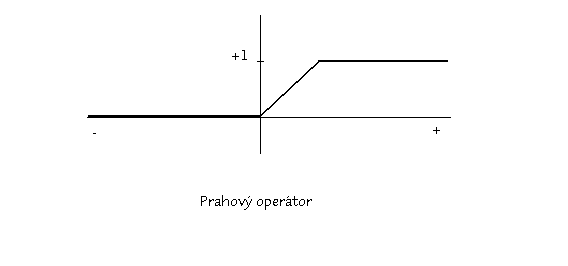
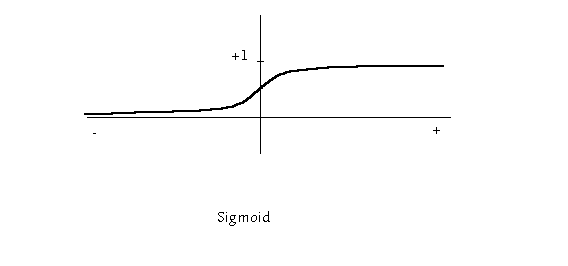
Popis typických modelů
Neurologické
Brain without Mind
Tento model poměrně přesně popisuje funkci neuronu a nezabývá se strukturou sítě. Síť je synchroní, tj. všechny neurony provádějí své akce ve stejný okamžik po časových úsecích  . Neuron i je charakterizován:
. Neuron i je charakterizován:
- stavem
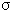 i =
i = 1
1 - zda pálí ,či nepálí
- sílami synapsí wji
- wji>0 je excitační spojení od neuronu j, wji<0 je inhibiční spojení a wij=0 značí nespojeno
- prahem pálení w0i
- poločasem rozpadu aktivity ti
- označuje přirozený pokles aktivity neexcitovaného neuronu
- aktivitou ui
- pro kterou platí:
ui(t+)=jwij*(j(t)+1)/2 + exp(-/ti(t))*ui(t)*(1-i(t))
- refraktorním obdobím R
- čas nutný k restauraci sil. R se pohybuje okolo 1 až 5 .
- V modelu se zavádí stavová proměnná ri(t):
- ri(t+)=ri(t)+1 ... pokud i(t)=-1
ri(t+)=-R ... pokud i(t)=+1
- Pravděpodobnost, že neuron pálí je určena jeho aktivitou:
- p{i(t)=+1} =f(ui(t)-w0i(t))*
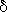 i(t)
i(t)
kde i(t)=0, pokud ri<0, i(t)=1 jinak
funkce f je sigmoid: f(x)=eTx/(eTx+1) T>=0
Síť neuvažuje pravidla pro adaptaci parametrů. Tato síť je spíše "úvodní pronikání" do možností, které výpočetní technika neurologii nabízí.
Goldschlagerův model vyšších mozkových funkcí
Za základní element si Goldschlager zvolil tzv. modul (column, sloupec). Při anatomickém popisu mozkové kůry lze vysledovat pravidelně se opakující sloupcové struktury, které jsou stavebnímy kameny mozkové kůry, ale ohraničení těchto modulů je neurčité a v různých částech kůry mají různou strukturu (např. chybí některá z 6-ti buněčných vrstev apod.). Proto je položení modulu jako základní funkční jednotky umělým zjednodušením. Modul sestává řádově z 1000 neuronů a je spojen jednak s ostatními moduly, jednak s receptory a efektory.
Goldshlagerova síť formálních neuronů má rovinnou topologii a je strukturálně homogenní. Důležitý je pojem směru. Každý modul umí:
- signál přijatý z daného směru vyslat do směru opačného
- kmitat o vlastní frekvenci, úměrné přijatým signálům
- tzv. habituaci, tj. pozvolný útlum při dlouhodobé aktivaci
- pamatovat si a preferovat směry, ze kterých přicházejí větší signály tehdy, je-li modul sám aktivní (tzv. Hebbův zákon)
Goldshlager tedy vychází z představy, že podstatné na činnosti mozkové kůry je, že je to povrch mozku a myšlení chápe jako jakousi topologickou aktivitu tohoto povrchu.
Aplikační nestrukturované
Barto
Tento model je typický pro první vlnu zájmu o neuronové sítě. Základní myšlenku lze shrnout takto: Pospojujeme-li dostatečný počet neuronů a postavíme je před úlohu, síť si již sama vytvoří vhodnou strukturu vazeb, která bude optimální vzhledem k dané úloze. Barto se nechal inspirovat Dawkinsonovou představou sobeckého chování základního elementu, který se snaží maximalizovat své vstupy dle svého měřítka hodnot.
Popis formálního neuronu:
- Vstupy:
- obvyklé vstupy:
- x1..xn=1
- r=1
- reinforcement, informace o správnosti výstupu sítě, v podstatě výukový signál. Od klasického výukového signálu se liší tím, že nedává informaci, jaký měl být výstup tohoto prvku, ale pouze globální informaci o celé síti.
- Výstup:
- prvek pracuje v diskrétním čase.
- Krok prvku:
-
- s(t)=iwi(t)xi(t)
- aktivita neuronu
- y(t)=+1
- pokud s(t)+
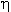 >0
>0
- y(t)=-1
- jinak
určení výstupu neuronu, je náhodná veličina s nulovou střední hodnotou, tzv. vnitřní práh šumu
- wi(t+1)=wi(t)+
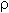 *(y(t)-E{y(t)|s(t)})*xi pro r=+1
*(y(t)-E{y(t)|s(t)})*xi pro r=+1
- wi(t+1)=wi(t)+*
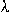 (-y(t)-E{y(t)|s(t)})*xi pro r=-1
(-y(t)-E{y(t)|s(t)})*xi pro r=-1
- úprava vah. E{y(t)|s(t)} je střední hodnota y(t) při s(t),>0, 0<=<=1 parametry učení
Neuron zde maximalizuje pravděpodobnost, že obdrží reinforcement +1. Ovšem již u jediného neuronu trvá tato maximalizace řádově 1000 pokusů. V síti je postavení vnitřních neuronů (tj. těch jejichž výstup není výstupem sítě) o to horší, že reinforcement je do jisté míry nezávyslý na jejich činnosti.
Hopfield-Boltzmann
Topologie sítí je naprosto homogenní, každý neuron je spojen se všemi ostatnímy a tato spojení jsou symetrická, tj. wij=wji. Velikosti vah mohou být libovolné. Každý neuron je popsán:
- aktivačním potenciálem x=1
- prahem pálení
Motivační ideou Boltzmanovy sítě je představa, že síť je soustava částic, která se snaží zaujmout stav s nejmenší energií. Energie je zde definována sztahem:
- E=-i<j(wij*xi*xj)+ii*xi
Hodnoty xi jsou interpretovány jako fyzikální stavy částic, wij jako slučitelnost (wij>0 značí slučitelnost, wij<0 neslučitelnost a wij=0 neexistenci vztahu) stavů xi=1 a xj=1. Práh i reprezentuje vnitřní energii stavu xi=1.
Z požadavku minimalizace energie plyne jednoduché rozhodovací pravidlo:
- xk=fk(wik*xi)
kde fk je skokový operátor s prahem k
Práce sítě pak vypadá takto:
- nastavení potenciálů na vstupní vzor
- Iterace dle předchozího pravidla až do ustálení
Podle toho, zda v 2. kroku pracují všechny elementy najednou, nebo pouze jeden, rozlišujeme sítě synchroní a asynchroní. Představme si síť se třemi neurony, která pracuje asynchroně:
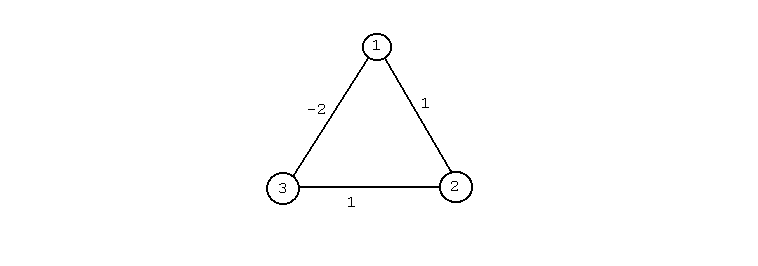
Práce sítě je pak zaznamenána v následující tabulce:
| stav | vektor | 1 | 2 | 3 |
| 0 | 0 0 0 | 4 | 2 | 1 |
| 1 | 0 0 1 | 1 | 3 | 1 |
| 2 | 0 1 0 | 6 | 2 | 3 |
| 3 | 0 1 1 | 3 | 3 | 3 |
| 4 | 1 0 0 | 4 | 6 | 4 |
| 5 | 1 0 1 | 1 | 7 | 4 |
| 6 | 1 1 0 | 6 | 6 | 6 |
| 7 | 1 1 1 | 3 | 7 | 6 |
Z grafu je pak vidět, že síť se ustálí ve stavu s minimální energií.
Toto minimum je však lokální. Při řešení problému lokality se však jednotlivé modely rozcházejí. Boltzmanova síť, která v kroku 1. nastavuje napevno jen několik neuronů a potřebuje, aby zbytek zaujal za těchto podmínek stav o nejmenší energii, k sumě v přechodovém pravidle přičítá náhodnou veličinu s nulovou střední hodnotou - analogie tepelného pohybu částic:
- xk=fk(wik*xi+)
Hopfieldova síť pracuje s deterministickou variantou přechodového pravidla a inicializuje váhy tak, aby každé lokální minimum odpovídalo jedné z rozpoznávaných kategorií.
Váhy lze nastavovat tvrdě dosazením (varianta s učitelem):
- wij=xixj
kde xi a xj jsou prvky vzorů k rozpoznávání, přes které probíhá suma,
nebo se průběžně adaptují na vstupní vzory:
- wij=wij+
 *(pij-píj)
*(pij-píj)
kde pij je relativní četnost současného výskytu stavů xi=1 a xj=1 při vnější stimulaci a píj je tato četnost bez vnější stimulace.
Tato síť je účinná asociativní paměť, ale má některé nedostatky:
- je vysoce náročná na počet spojení
- brzy se přeplní (doporučuje se ukládat méně exemplářů než 15% počtu neuronů
- exemplář může být nestabylní (tj. konvergovat k jinému)
Aplikační strukturované
Hierarchické
Uvažujme neuron s w1=w2=1, =1.5 a se skokovým operátorem. Takový neuron realizuje logickou funci and. Rovnici x1+x2+1.5=0 můžeme chápat jako přímku s normálovým vektorem (1,1) a posunutím 1.5. Potom rovnice f(x1+x2+1.5)=1 znamená, zda vektor (x1,x2) leží nad nebo pod danou přímkou.
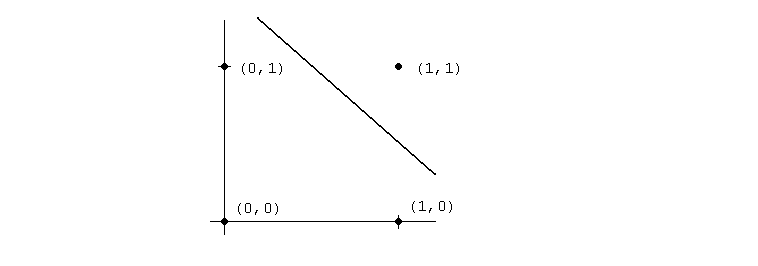
Obecně pak jeden neuron rozlišuje poloprostory určené nadrovinou určenou normálou w=(w1,w2,...,wn) a posunutím . Protože perceptrony mohou vykonávat logické funkce and a or, dvouvrstvá síť už bude umět rozpoznávat konvexní oblasti a třívrstvá síť již libovolné oblasti v prostoru vstupních vektorů. Je-li jako signální funkce použit sigmoid, jsou oblasti ohraničeny hladkými křivkami. Zatímco však výuka jediného neuronu je celkem jednoduchá:
- wi(nová)=wi(stará)+*(žádaný výstup-skutečný výstup)*xi
na výuku vícevrstvých sítí dlouho nebyly známy účinné algoritmy. Teprve v 70-tých letech byl oběven bacpropagation algoritus, který pracuje velmi úspěšně, ačkoliv jeho konvergence není prokázána. Je založen na probublávání opravené informace od výstupní vrstvy ke vstupní:
- nastav prahy a váhy na malá náhodná čísla
- vlož vstup x1,..,xn a žádaný výstup d1,..,dm
- vypočti výstup
- uprav váhy: wij(t+1)=wij(t)+*jxí
- kde xí je hodnota na i-vstupu perceptronu j
j je chyba perceptronu j:
j je výstupní ... j=yj(1-yj)*(dj-yj)
j není výstupní ... j=xj´(1-xj´)*k z vrstvy nad j (k*wjk)
- opakuj od kroku 2.
Tento algoritmus reprezentuje minimalizaci střední kvadratické chyby gradientovým hledáním. Na to, že gradientové techniky hledají lokální minimum, pracuje tento algoritmus překvapivě dobře.
Kompetiční modely
Tyto architektury byly vyvinuty v 70-tých letech. Základní struktura je dvouvrstvá: vrstva F1 je vstupní, v jejích synapsích do vrstvy F2 jsou zakódovány typické exempláře rozpoznáváných tříd. Ve vrstvě F2 jsou vzájemné vazby inhibiční, takže F2 provádí jakýsi výběr ze vstupů. Většinou je F2 konstruována tak, aby v ní po ustálení byl aktivní právě jeden neuron reprezentující určitou třídu. Váhy mezi F1 a F2 se adaptují podle přicházejících hodnot a aktivity cílového neuronu.
Hammingova síť
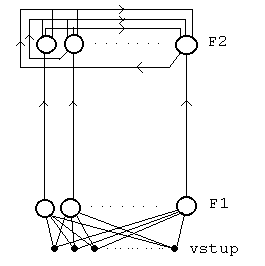 Tato síť je nejjednodušším příkladem třídy kompetičních modelů. Jedná se o variantu s učitelem a binárním vstupem. Lze ji také popsat jako třídič dle nejmenší chyby: k danému vstupu najde kategorii jejíž reprezentant má od vstupu nejmenší tzv. Hammingovu vzdálenost (tj počet odlišných vstupů). První vrstva sítě počítá Hammingovu vzdálenost (přesněji doplněk), druhá laterální inhibicí vybírá maximum - tedy správnou kategorii. Síť pracuje podle násleujícího algoritmu:
Tato síť je nejjednodušším příkladem třídy kompetičních modelů. Jedná se o variantu s učitelem a binárním vstupem. Lze ji také popsat jako třídič dle nejmenší chyby: k danému vstupu najde kategorii jejíž reprezentant má od vstupu nejmenší tzv. Hammingovu vzdálenost (tj počet odlišných vstupů). První vrstva sítě počítá Hammingovu vzdálenost (přesněji doplněk), druhá laterální inhibicí vybírá maximum - tedy správnou kategorii. Síť pracuje podle násleujícího algoritmu:
- inicializace (tj. výuka):
- F1: wij=-jxi/2
- váhy mezi i-tým vstupem a j-tým neuronem. jxi je i-tý prvek exempláře j-té kategorie. Prvky exemplářů jsou rovny 1.
j=N/2 - N je počet vstupů (bodů vstupních vzorů)
- F2: tkk=1, tk1=- pro k
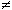 1
1 - váhy ve vrstvě F2, je parametr síly laterální inhibice
j=0
- výpočet:
- nový vstup (x1,..,xn)
-
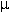 j(0)=ft(wij*xi+j) ... krok F1
j(0)=ft(wij*xi+j) ... krok F1
- j(t+1)=ft((t)-*kjk(t))...krok F2
- krok 3. se opakuje do ustálení.
- j(t) je výstup j-tého neuronu v čase t.
Po ustálení je v F2 aktivní právě jeden neuron - vstup byl nejpodobnější kategorii, kterou on reprezentuje.
ART
Kompetiční modely mají výraznou slabinu. Problémem je jejich přílišná plasticita, tj. schopnost se učit, která umožňuje vymazat předchozí naučené kategorie. Ve fázi adaptace se tak může kategorie výrazně změnit, posunout na úplně jiné místo v prostoru vstupních vzorů. Jedním z možných způsobů, jak tento problém při zachování ostatních vlastností řešit, je testovat při rozpoznávání skutečnou míru podobnosti vstupního vzoru a rozpoznané kategorie. Tento přístup používá architektura Adaptive Resonance Theory - ART.
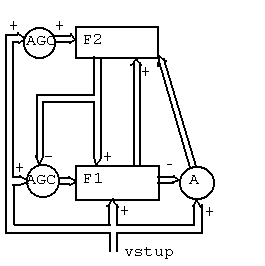 V systému jsou dva důležité podsystémy, zajišťující účinnou komunikaci mezi F1 a F2. Jsou to
V systému jsou dva důležité podsystémy, zajišťující účinnou komunikaci mezi F1 a F2. Jsou to - orientační systém: předává vrstvě F2 zprávu o úspěšnosti srovnání v F1
- AGC: tzv. systém řízení zisku (Attentional Gain Control).
Srovnávací vrstva F1 je excitována jak z F2, tak ze vstupu, ale pouze na vstup by měla reagovat nadprahově. Tuto úlohu zajišťuje AGC jako tzv. pravidlo 2/3 - dvou ze tří. Vrstva F1 má tři vstupy: vnější vstup, F2 a AGC. Její dynamika je nastavena tak, aby pro nadprahovou excitaci bylo zapotřebí alespoň dvou vstupů.
Síť pracuje takto:
- Vnější vstup zaktivizuje F1, v níž vznikne jeho kopie. Tato zaktivizuje F2, kde proběhne laterální inhibice a vybere se nejbližší kategorie.
- Vzor reprezentující tuto kategorii je vyslán zpět do F1 a porovnán s vnějším vstupem.
- Je-li rozdíl těchto vzorů příliš velký, inhibuje se v F2 aktuální kategorie. Návrat na 1.
- Není-li tento rozdíl větší než předem stanovená míra bdělosti (vigilance), nastává úprava vah: váhy z F2 do F1, tedy vlastně exemplární vzor aktuální kategorie, se upraví na vstupní vzor, váhy z F1 do F2 se upraví tak, aby daný vstup přímo aktivoval právě tuto kategorii.
Stavu, ve kterém se síť nalézá ve 4. kroku, se nazývá resonance, neboť F1 a F2 se navzájem "podporují", tj. svou činností stabilizují vzor v té druhé. K resonanci a úpravám vah však nedojde, bude-li splněna podmínka kroku 3. pro všechny kategorie. Pak bude po celou dobu probíhat vyhledávací cyklus a struktura již naučeného nebude zničena.
Kohonenova síť
Tato síť je jiným možným řešením problému stability - je učení schopná pouze v mládí, s rostoucím časem ztrácí pružnost. Síť je opět dvouvrstvý model, ale na F2 je zavedena topologie. Blízké neurony pak rozpoznávají podobné kategorie. Popis algoritmu:
- inicializace:
- wij(0)=malá náhodná čísla ... váhy z F1 do F2
- Sj(0) ... množina sousedů neuronu j z F2.
Obvyklé zavedení pojmu sousedství:
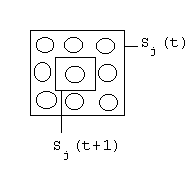
0<<1 ... rychlost učení
výpočet: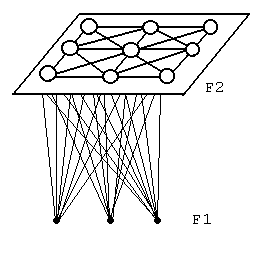
- nový vstup (x1,..,xn)
- výpočet vzdáleností k exemplářům kategorií: dj=|xi-wij(t)|
- výběr minima laterální inhibicí dj*=min{dj}
- adaptace: pro všechna j z Sj*(t):
- wij(t+1)=wij+(t)*(xi(t)-wij(t))
- Sj(t+1)=zmenšení Sj(t)
- (t+1)=zmenšení (t)
- opakuj od kroku 1.
Postupná ztráta samoučící se schopnosti určuje oblast použití sítě. Je vhodná tam, kde je třeba stabilní třídič dat, který při provozu své vlastnosti již nemění, nicméně se na počátku práce přizpůsobí struktuře vstupů. Výsledek je však závyslý na pořadí vstupů, proto je nutné fázi učení věnovat zvýšenou pozornost.
Literatura:
Petr Jaklin: Neuronové sítě
Gurney: Neural Nets
Kröse, Smagt: An Introduction to Neural Networks